https://deepmind.com/blog/alphago-zero- ... g-scratch/
Holy crap!!
AlphaGo Zero: Learning from scratch
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
-
jeromie
- Lives in sente
- Posts: 902
- Joined: Fri Jan 31, 2014 7:12 pm
- Rank: AGA 3k
- GD Posts: 0
- Universal go server handle: jeromie
- Location: Fort Collins, CO
- Has thanked: 319 times
- Been thanked: 287 times
Re: AlphaGo Zero: Learning from scratch
I got to this point and felt surprised...
and then I kept going and got to this point:

Wow, this is so cool! I desperately hope they release self-play games from this version.
AlphaGo Zero skips this step and learns to play simply by playing games against itself, starting from completely random play. In doing so, it quickly surpassed human level of play and defeated the previously published champion-defeating version of AlphaGo by 100 games to 0.
and then I kept going and got to this point:
It also differs from previous versions in other notable ways.
- AlphaGo Zero only uses the black and white stones from the Go board as its input, whereas previous versions of AlphaGo included a small number of hand-engineered features.
- It uses one neural network rather than two. Earlier versions of AlphaGo used a “policy network” to select the next move to play and a ”value network” to predict the winner of the game from each position. These are combined in AlphaGo Zero, allowing it to be trained and evaluated more efficiently.
- AlphaGo Zero does not use “rollouts” - fast, random games used by other Go programs to predict which player will win from the current board position. Instead, it relies on its high quality neural networks to evaluate positions.
Wow, this is so cool! I desperately hope they release self-play games from this version.
-
jeromie
- Lives in sente
- Posts: 902
- Joined: Fri Jan 31, 2014 7:12 pm
- Rank: AGA 3k
- GD Posts: 0
- Universal go server handle: jeromie
- Location: Fort Collins, CO
- Has thanked: 319 times
- Been thanked: 287 times
Re: AlphaGo Zero: Learning from scratch
Sorry for double posting, but I just glanced at the freely available version of the paper (don't have time for more right now).
A couple interesting points:
AlphaGo learned and used several common joseki sequences during the course of learning. They show when in the training process it learned each one and which it preferred at various stages.
The full online version(only available with a Nature subscription) (edit: as Uberdude pointed out, this was wrong) includes the first 100 moves of several games at various points in the learning process.
A couple interesting points:
AlphaGo learned and used several common joseki sequences during the course of learning. They show when in the training process it learned each one and which it preferred at various stages.
The full online version
Last edited by jeromie on Wed Oct 18, 2017 10:38 am, edited 1 time in total.
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
Re: AlphaGo Zero: Learning from scratch
https://deepmind.com/documents/119/agz_ ... nature.pdf has many game diagrams in the appendixjeromie wrote: The full online version (only available with a Nature subscription) includes the first 100 moves of several games at various points in the learning process.
EDIT: and Andrew Jackson just posted a zip of the sgfs on reddit:
https://www.nature.com/nature/journal/v ... 270-s2.zip
An example AG Zero beating AG Master:
-
Kirby
- Honinbo
- Posts: 9553
- Joined: Wed Feb 24, 2010 6:04 pm
- GD Posts: 0
- KGS: Kirby
- Tygem: 커비라고해
- Has thanked: 1583 times
- Been thanked: 1707 times
Re: AlphaGo Zero: Learning from scratch
Fun to watch the progression among the self-play games.
One of the earlier games:
And after a bit of learning from self-play:
One of the earlier games:
And after a bit of learning from self-play:
be immersed
-
alphaville
- Dies with sente
- Posts: 101
- Joined: Sat Apr 22, 2017 10:28 pm
- GD Posts: 0
- Has thanked: 24 times
- Been thanked: 16 times
Re: AlphaGo Zero: Learning from scratch
So the "20 block" self-play games are from various stages of training, while the "40 block" folder come only from the strongest version?Kirby wrote:Fun to watch the progression among the self-play games.
That is confusing, I wish that they labeled the "in-training" games somehow, to be able to tell the strength.
-
alphaville
- Dies with sente
- Posts: 101
- Joined: Sat Apr 22, 2017 10:28 pm
- GD Posts: 0
- Has thanked: 24 times
- Been thanked: 16 times
Re: AlphaGo Zero: Learning from scratch
I think I got it now: both groups of self-play games show progression during training, according to Nature.alphaville wrote:So the "20 block" self-play games are from various stages of training, while the "40 block" folder come only from the strongest version?Kirby wrote:Fun to watch the progression among the self-play games.
That is confusing, I wish that they labeled the "in-training" games somehow, to be able to tell the strength.
For the "20 block" folder:
"The 3-day training run was subdivided into 20 periods. The best player from each period (as selected by the evaluator) played a single game against itself, with 2 h time controls"
For the 40-block" folder:
"The 40-day training run was subdivided into 20 periods. The best player from each period (as selected by the evaluator) played a single game against itself, with 2 h time controls."
If the "20 periods" are divided equally by time, then the weakest game in the 40-bucket folder matches random-playing engines, 2nd game matches engines after 2 days of training, etc.
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
Re: AlphaGo Zero: Learning from scratch
Yes, AlphaGo is an international effort and shows the remarkable success that comes from assembling the best talents from around the world. I really wonder if it would still be possible post-Brexit. Maybe so as Google is a big rich name with admin staff to help sponsor through our kafkaesque visa process, but maybe not...Marcel Grünauer wrote:A patriotic side note - I just learned that Julian Schrittwieser, one of the main authors of that paper, is from Austria and studied at the Technical University of Vienna. He has worked for Google since 2012 and switched to DeepMind when he heard Demis Hassabis talk about AlphaGo. His background is, naturally, in machine learning.
-
RobertJasiek
- Judan
- Posts: 6283
- Joined: Tue Apr 27, 2010 8:54 pm
- GD Posts: 0
- Been thanked: 800 times
- Contact:
Re: AlphaGo Zero: Learning from scratch
It is not like all best talents would be in one place. Rather call it a "selection of some of the allegedly best talents"Uberdude wrote:the best talents
***
Elsewhere, I read about a plan to learn "the" rules on its own. a) If this relies on an input of existing played games, it is possible. b) If there is nothing but the playing material, there cannot be a learning of _the_ rules - there can only be a learning of possible rulesets of possible games that might be played with the playing material.
***
Learning from scratch so fast and successfully is exceptionally impressive. However, it is still possible that AlphaGo Zero fails at expert positions that rarely occur in practical play. IOW, neural nets can err. Self-driving cars can kill. Self-replicating or war-fighting AI-(nano)-robots might cause extinction of mankind. We must never forget this, regardless however impressive an AI might seem.
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
Re: AlphaGo Zero: Learning from scratch
There was some welcome clarification about the different versions of AlphaGo, from the Methods section; though no mention of Ke Jie version (this paper was submitted before that match, sitting on a big secret!) but I think that and the 55 self-play released after were basically the same as Master with just minor incremental improvements (I think not exactly the same: 55 self-play version does seem to like early 3-3 more than online 60 Master version, and that's so early it can't be explained away as the more chaotic style can with "when it is winning against weak humans it simplifies, but against itself it plays 100%").
AlphaGo versions We compare three distinct versions of AlphaGo:
1. AlphaGo Fan is the previously published program that played against Fan Hui in October
2015. This program was distributed over many machines using 176 GPUs.
2. AlphaGo Lee is the program that defeated Lee Sedol 4–1 in March, 2016. It was previously
unpublished but is similar in most regards to AlphaGo Fan . However, we highlight several
key differences to facilitate a fair comparison. First, the value network was trained from
the outcomes of fast games of self-play by AlphaGo, rather than games of self-play by the
policy network; this procedure was iterated several times – an initial step towards the tabula
rasa algorithm presented in this paper. Second, the policy and value networks were larger
than those described in the original paper – using 12 convolutional layers of 256 planes
respectively – and were trained for more iterations. This player was also distributed over
many machines using 48 TPUs, rather than GPUs, enabling it to evaluate neural networks
faster during search.
3. AlphaGo Master is the program that defeated top human players by 60–0 in January, 2017.
It was previously unpublished but uses the same neural network architecture, reinforcement
learning algorithm, and MCTS algorithm as described in this paper. However, it uses the
same handcrafted features and rollouts as AlphaGo Lee and training was initialised by
supervised learning from human data.
4. AlphaGo Zero is the program described in this paper. It learns from self-play reinforcement
learning, starting from random initial weights, without using rollouts, with no human supervision,
and using only the raw board history as input features. It uses just a single machine
in the Google Cloud with 4 TPUs (AlphaGo Zero could also be distributed but we chose to
use the simplest possible search algorithm).
-
pookpooi
- Lives in sente
- Posts: 727
- Joined: Sat Aug 21, 2010 12:26 pm
- GD Posts: 10
- Has thanked: 44 times
- Been thanked: 218 times
Re: AlphaGo Zero: Learning from scratch
Aja Huang mentioned that it is the same version but slightly stronger (perhaps due to longer time setting?)
source: http://sports.sina.com.cn/go/2017-05-24 ... 9285.shtml
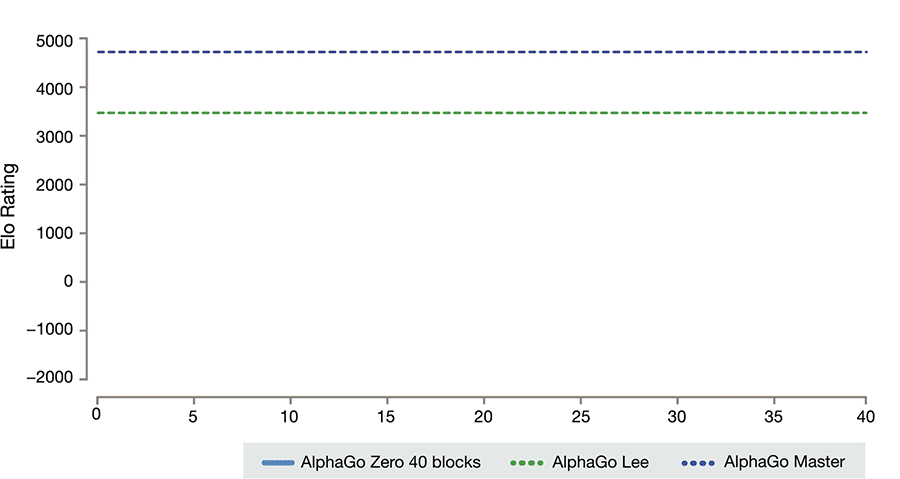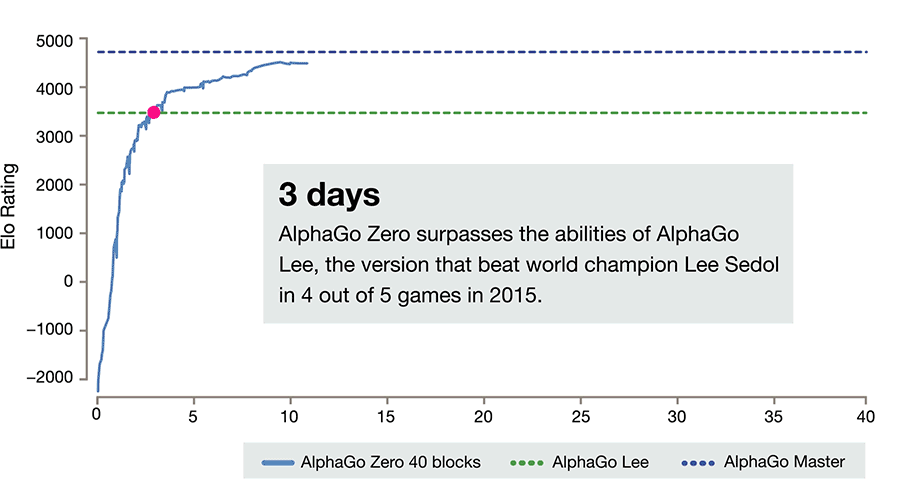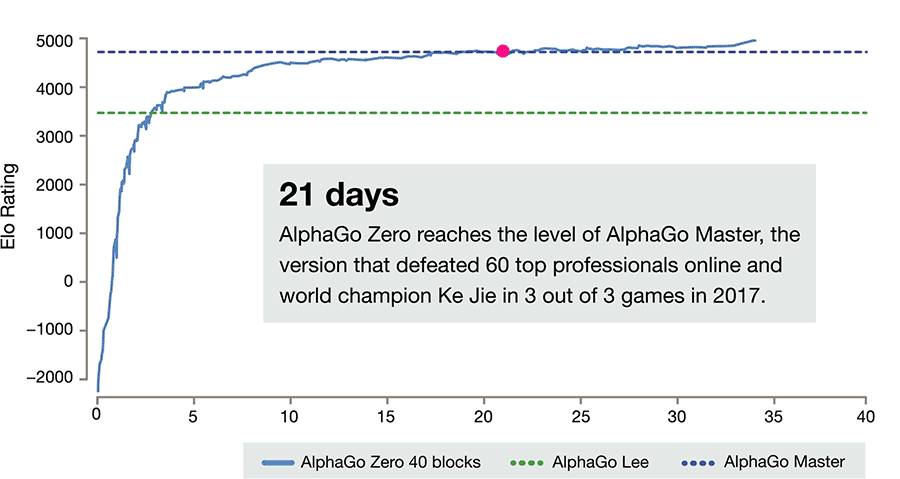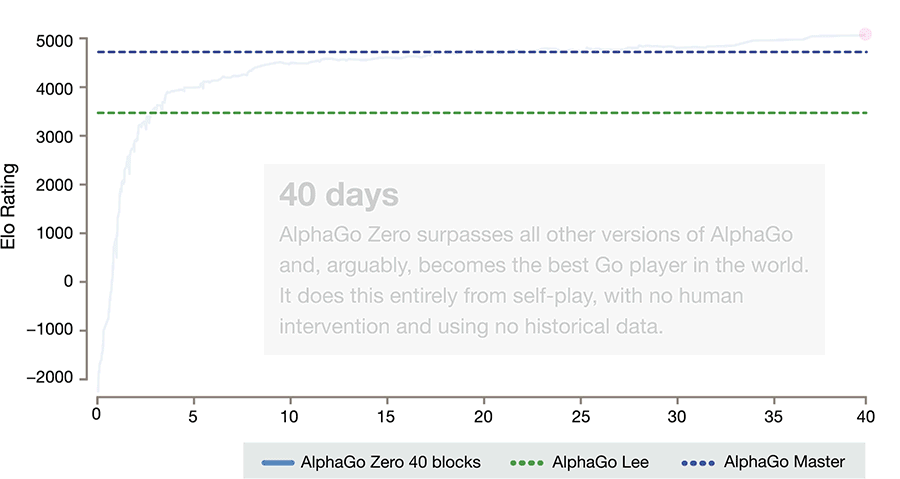
Also in the DeepMind website there's animated graph that says Master version and version that play 3 match with Ke Jie is the same version
source: https://storage.googleapis.com/deepmind ... 20Time.gif
source: http://sports.sina.com.cn/go/2017-05-24 ... 9285.shtml
Also in the DeepMind website there's animated graph that says Master version and version that play 3 match with Ke Jie is the same version
source: https://storage.googleapis.com/deepmind ... 20Time.gif
{kind=link}
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
Re: AlphaGo Zero: Learning from scratch
So what new moves is AlphaGo Zero playing? One very noticeable pattern in the AlphaGo Zero (40 blocks) [strongest version] vs AlphaGo Master 20 games is shown below. This happens after a low plus high double approach against a 4-4. This in itself is remarkable as AlphaGo Master so rarely pincered approaches to its 4-4s that such opportunities rarely arose. However, AG Zero seems to like pincering a lot more now, often the 3-space low, or 2-space high as below. This corner sequence happened in 8 games of the 20, with AG Zero always being the one capturing the inside stones, and it won 7 of the 8 games. So it seems like AG Zero thinks it is even to good for it, and AG Master likewise thinks the sequence from the other side is even to good for it, but probably AG Zero is closer to the truth given the results/strengths. According to waltheri this sequence has never happened before in pro games. My initial feeling was it looked an interesting sacrifice for white compared to the normal entering the corner after attachment (maybe with hane first) and you also get some nice forcing moves on the outside with the cut aji, but set against that black is solid and almost 100% alive which AG tends to place a lot of value on (and white isn't: in some games the white group gets into trouble later; but actually in the one game AG Master won the black group does die!).
-
tartaric
- Dies in gote
- Posts: 24
- Joined: Tue Aug 29, 2017 11:59 am
- GD Posts: 0
- KGS: 4 dan
- Has thanked: 1 time
Re: AlphaGo Zero: Learning from scratch
This version is the one which played Ke Jie so not that strong cause Ke matched it equally during the first game and also Alpha go Master managed to win some games in the 20 games serie which was released.