I actually think that for mid to high dan level amateurs, there is some usefulness here. I'm below the necessary strength to derive a lot of value out of these variations, but I browsed through and still learned some things about openings that I actually encounter from both sides - the chinese, the mini chinese, the kobayashi, san-ren-sei. Moves that I wouldn't have even considered that I can experiment with now that I know that they're possible, or some moves that I would have considered and rejected as bad instead being evaluated as not-bad by AlphaGo with a simple and clear variation that disproves my misconception.
I also think that at the extremes the evaluations are useful at dan level. Mostly when they get noticeably outside the 40%-60% range I find that I'm more likely than not to myself feel dissatisfied with the side that supposedly fell behind - and that gives me some confidence that the evals, once they get that extreme, are at the right level to be at least somewhat informative. I wouldn't put huge value on it at amateur dan, but at minimum you can still use it as another good hundred datapoints for improving one's overall sense of direction of play and whole-board judgment, one more drop in the bucket.
AlphaGo Teach discussion (Go Tool from DeepMind)
-
lightvector
- Lives in sente
- Posts: 759
- Joined: Sat Jun 19, 2010 10:11 pm
- Rank: maybe 2d
- GD Posts: 0
- Has thanked: 114 times
- Been thanked: 916 times
-
moha
- Lives in gote
- Posts: 311
- Joined: Wed May 31, 2017 6:49 am
- Rank: 2d
- GD Posts: 0
- Been thanked: 45 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
I think they simply mean the MCTS effort / iterations / node expands. EDIT: Actually this was Master still so rollouts as well.Bill Spight wrote:From the web site:Simulations of what, pray tell?each move’s winning probability was computed by running an independent search of 10 million simulations from that position.
-
Bill Spight
- Honinbo
- Posts: 10905
- Joined: Wed Apr 21, 2010 1:24 pm
- Has thanked: 3651 times
- Been thanked: 3374 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
If so, the win rates should be perfect for SDKs, eh?moha wrote:I think they simply mean the MCTS effort / iterations / node expands. EDIT: Actually this was Master still so rollouts as well.Bill Spight wrote:From the web site:Simulations of what, pray tell?each move’s winning probability was computed by running an independent search of 10 million simulations from that position.
The Adkins Principle:
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
-
John Fairbairn
- Oza
- Posts: 3725
- Joined: Wed Apr 21, 2010 3:09 am
- Has thanked: 20 times
- Been thanked: 4739 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
The wording of the announcement is unclear as regards selection of "major" variations or indeed what is meant by "opening" (fuseki or joseki - I infer the former).
But insofar as I can make sense of it, the results don't seem to equate with pro tournament practice and the human moves shown must therefore be from a mix of pro and ama games but mostly ama.
If I follow the first two recommended moves (R16 then Q4) DeepMind gives 11 human moves: C17, C16, C15, C4, D17, D16, D4, D3, E17, O3 and P17.
But doing a similar exercise on a pro tournament database (approx. 90,000 games) gives a quite different result with 21 moves tried by humans, Human pros did not try the O3 given above, but did try the rest plus C5, C3, D15, D14, D5, E16, E4, E3, O17, P16 and R6.
The AG win rates are potentially interesting (but how much different from pro win rates as shown by Kombilo?), but if they include many wins against amateurs (and/or internet blitz games) they may be somewhat spurious. It would be nice if Nature could be cajoled into including a properly versed go player as one of their referees.
Just offering users the chance to find plays they have never considered before and thus be "creative" (sounds like an AI definition of the word) is not much of a selling point given the wealth of pro games around, and specifically those that were experimental such as New Fuseki, that already do that.
But insofar as I can make sense of it, the results don't seem to equate with pro tournament practice and the human moves shown must therefore be from a mix of pro and ama games but mostly ama.
If I follow the first two recommended moves (R16 then Q4) DeepMind gives 11 human moves: C17, C16, C15, C4, D17, D16, D4, D3, E17, O3 and P17.
But doing a similar exercise on a pro tournament database (approx. 90,000 games) gives a quite different result with 21 moves tried by humans, Human pros did not try the O3 given above, but did try the rest plus C5, C3, D15, D14, D5, E16, E4, E3, O17, P16 and R6.
The AG win rates are potentially interesting (but how much different from pro win rates as shown by Kombilo?), but if they include many wins against amateurs (and/or internet blitz games) they may be somewhat spurious. It would be nice if Nature could be cajoled into including a properly versed go player as one of their referees.
Just offering users the chance to find plays they have never considered before and thus be "creative" (sounds like an AI definition of the word) is not much of a selling point given the wealth of pro games around, and specifically those that were experimental such as New Fuseki, that already do that.
-
moha
- Lives in gote
- Posts: 311
- Joined: Wed May 31, 2017 6:49 am
- Rank: 2d
- GD Posts: 0
- Been thanked: 45 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
Master itself did OK, looking only at these numbers, didn't it?Bill Spight wrote:If so, the win rates should be perfect for SDKs, eh?moha wrote:I think they simply mean the MCTS effort / iterations / node expands. EDIT: Actually this was Master still so rollouts as well.
Again, I think these are only probabilites, estimated by AG with a deep search (and rollouts with the reduced policy net). So there should be some correlations to actual pro data, but significant differences as well.John Fairbairn wrote:The AG win rates are potentially interesting (but how much different from pro win rates as shown by Kombilo?), but if they include many wins against amateurs (and/or internet blitz games)
-
Baywa
- Dies in gote
- Posts: 39
- Joined: Wed Feb 22, 2017 6:37 am
- GD Posts: 0
- Has thanked: 40 times
- Been thanked: 10 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
For what it's worth: I think one can find the games that AlphaGo played against humans inside that tree of variations. For example (I tried that out) game No. 18 of Master (Black) against Ke Jie is contained and one can follow AlphaGo's evaluations. Interestingly, Master does not always choose the "best" continuation. OTOH, when Ke Jie played 22 M4 AlphaGo's winning percentage rose to 49.9 percent. The move suggested as alternative, which defended the l.l. corner would have kept Blacks winning percentage at 47.7.
So it might be worthwhile to follow these evaluations.
So it might be worthwhile to follow these evaluations.
Couch Potato - I'm just watchin'!
-
Bill Spight
- Honinbo
- Posts: 10905
- Joined: Wed Apr 21, 2010 1:24 pm
- Has thanked: 3651 times
- Been thanked: 3374 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
No. Master had/has a value network and did not rely upon MCTS quasi-random rollouts alone. Also, Master built a game tree and did not rely solely upon "win rates".moha wrote:Master itself did OK, looking only at these numbers, didn't it?Bill Spight wrote:If so, the win rates should be perfect for SDKs, eh?moha wrote:I think they simply mean the MCTS effort / iterations / node expands. EDIT: Actually this was Master still so rollouts as well.
Again I ask, what were they simulating?
The Adkins Principle:
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
-
yoyoma
- Lives in gote
- Posts: 653
- Joined: Mon Apr 19, 2010 8:45 pm
- GD Posts: 0
- Location: Austin, Texas, USA
- Has thanked: 54 times
- Been thanked: 213 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
My interpretation is the process was:John Fairbairn wrote:The wording of the announcement is unclear as regards selection of "major" variations or indeed what is meant by "opening" (fuseki or joseki - I infer the former).
But insofar as I can make sense of it, the results don't seem to equate with pro tournament practice and the human moves shown must therefore be from a mix of pro and ama games but mostly ama.
If I follow the first two recommended moves (R16 then Q4) DeepMind gives 11 human moves: C17, C16, C15, C4, D17, D16, D4, D3, E17, O3 and P17.
But doing a similar exercise on a pro tournament database (approx. 90,000 games) gives a quite different result with 21 moves tried by humans, Human pros did not try the O3 given above, but did try the rest plus C5, C3, D15, D14, D5, E16, E4, E3, O17, P16 and R6.
The AG win rates are potentially interesting (but how much different from pro win rates as shown by Kombilo?), but if they include many wins against amateurs (and/or internet blitz games) they may be somewhat spurious. It would be nice if Nature could be cajoled into including a properly versed go player as one of their referees.
Just offering users the chance to find plays they have never considered before and thus be "creative" (sounds like an AI definition of the word) is not much of a selling point given the wealth of pro games around, and specifically those that were experimental such as New Fuseki, that already do that.
1) DeepMind picks a tree of interesting openings. From your analysis it seems maybe it included some amateur games. I view that as not a problem.
2) DeepMind uses AlphaGo Master to analyze every position in the tree, and puts the resulting winrates in the tree. This analysis has nothing to do with what winrates of pros or amateurs had from those positions. So your point about "wins against amateurs" doesn't apply. If there are some positions in there that are very bad (whether an pro or amateur got to that position is not relevant), Master will tell us so.
-
moha
- Lives in gote
- Posts: 311
- Joined: Wed May 31, 2017 6:49 am
- Rank: 2d
- GD Posts: 0
- Been thanked: 45 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
But why do you think these numbers are rollouts alone?Bill Spight wrote:No. Master had/has a value network and did not rely upon MCTS quasi-random rollouts alone. Also, Master built a game tree and did not rely solely upon "win rates".moha wrote:Master itself did OK, looking only at these numbers, didn't it?Bill Spight wrote:If so, the win rates should be perfect for SDKs, eh?
Again I ask, what were they simulating?
IMO these are Master's complete evaluations, 50% value net + 50% rollout (and Master is known to had weaker value net than Zero, weak enough that dropping rollouts would damage its strength in spite of the huge speedup - and I get the feeling that you equate NN policy-based rollouts to random rollouts of the past).
As for "simulations", I think this word is used for pure MCTS as well, even without rollouts. Such as X simulations = X leaf node expands (in the MCTS tree that Master does build, and which also contains estimated winrates, its only idea of value).
(The word may be a remnant of the idea that for a leaf node to be expanded, a new "simulation" is started from top, that takes a weighted-random branch at each node, until it reaches a leaf which is expanded.)
-
Bill Spight
- Honinbo
- Posts: 10905
- Joined: Wed Apr 21, 2010 1:24 pm
- Has thanked: 3651 times
- Been thanked: 3374 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
Bill Spight wrote:If so, the win rates should be perfect for SDKs, eh?
moha wrote:Master itself did OK, looking only at these numbers, didn't it?
Bill Spight wrote:No. Master had/has a value network and did not rely upon MCTS quasi-random rollouts alone. Also, Master built a game tree and did not rely solely upon "win rates".
Again I ask, what were they simulating?
I don't think that they are rollouts. They are "independent . . . simulations", according to the site. As such, they should actually be probability estimates.moha wrote: But why do you think these numbers are rollouts alone?
Maybe you are right.IMO these ARE Master's evaluations, 50% value net + 50% rollout (and Master is known to had weaker value net than Zero, weak enough that dropping rollouts would damage its strength in spite of the huge speedup - and I get the feeling that you equate NN policy-based rollouts to random rollouts of the past).
The Adkins Principle:
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
At some point, doesn't thinking have to go on?
— Winona Adkins
Visualize whirled peas.
Everything with love. Stay safe.
-
moha
- Lives in gote
- Posts: 311
- Joined: Wed May 31, 2017 6:49 am
- Rank: 2d
- GD Posts: 0
- Been thanked: 45 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
(Meanwhile I edited my post above to make it more clear.)
I don't think there are any other meaning behind these words than the amount of search done, and the resulting value estimate.
I don't think there are any other meaning behind these words than the amount of search done, and the resulting value estimate.
-
Uberdude
- Judan
- Posts: 6727
- Joined: Thu Nov 24, 2011 11:35 am
- Rank: UK 4 dan
- GD Posts: 0
- KGS: Uberdude 4d
- OGS: Uberdude 7d
- Location: Cambridge, UK
- Has thanked: 436 times
- Been thanked: 3720 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
Indeed, we can use this to find the mistakes of the pros who were losing by move 30 without making any obviously bad moves (actually I think some were fairly obviously bad once you looked at the games on mass, like premature hanging connection in the chinese opening 3-3 invasion and tenuki).Baywa wrote:For what it's worth: I think one can find the games that AlphaGo played against humans inside that tree of variations. For example (I tried that out) game No. 18 of Master (Black) against Ke Jie is contained and one can follow AlphaGo's evaluations. Interestingly, Master does not always choose the "best" continuation. OTOH, when Ke Jie played 22 M4 AlphaGo's winning percentage rose to 49.9 percent. The move suggested as alternative, which defended the l.l. corner would have kept Blacks winning percentage at 47.7.
So it might be worthwhile to follow these evaluations.
As for that Ke Jie game, I did think having to answer the slide at 3-3 was really painful, and quite probably more so that playing kosumi initially and letting black make whatever loose but not territory formation on the lower side.
I made a thread to highlight and discuss interesting moves/evaluations in this data: https://www.lifein19x19.com/viewtopic.php?f=15&t=15310.
-
djhbrown
- Lives in gote
- Posts: 392
- Joined: Tue Sep 15, 2015 5:00 pm
- Rank: NR
- GD Posts: 0
- Has thanked: 23 times
- Been thanked: 43 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
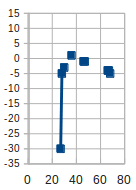
Alfie says all black's first moves are <50%, so either black should resign before placing a stone, or komi is too much.
- Attachments
-
- alfie.png (278.22 KiB) Viewed 15291 times
i shrink, therefore i swarm
-
pookpooi
- Lives in sente
- Posts: 727
- Joined: Sat Aug 21, 2010 12:26 pm
- GD Posts: 10
- Has thanked: 44 times
- Been thanked: 218 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
Unless the opponent is God, the resign threshold can be set well below 50%.djhbrown wrote:Alfie says all black's first moves are <50%, so either black should resign before placing a stone, or komi is too much.
And I'm wondering what rule AlphaGo calculate in. From the <50% Black winrate I bet it's Chinese. But DeepZenGo also give <50% to black in Japanese rule too.
-
vier
- Dies with sente
- Posts: 92
- Joined: Wed Oct 30, 2013 7:04 am
- GD Posts: 0
- Has thanked: 8 times
- Been thanked: 29 times
Re: AlphaGo Teach discussion (Go Tool from DeepMind)
The opening book "book.sgf" has KM[7.5] in the header.pookpooi wrote:And I'm wondering what rule AlphaGo calculate in. From the <50% Black winrate I bet it's Chinese.