I recently ran across a couple of articles on deep neural networks which may be pertinent. One is called "intriguing properties of neural networks" (
https://arxiv.org/abs/1312.6199 ). To quote from its abstract:
Deep neural networks are highly expressive models that have recently achieved state of the art performance on speech and visual recognition tasks. While their expressiveness is the reason they succeed, it also causes them to learn uninterpretable solutions that could have counter-intuitive properties.
Uninterpretable solutions with counter-intuitive properties? AlphaGo, anyone?

Second, we find that deep neural networks learn input-output mappings that are fairly discontinuous to a significant extent. We can cause the network to misclassify an image by applying a certain imperceptible perturbation, which is found by maximizing the network's prediction error. In addition, the specific nature of these perturbations is not a random artifact of learning: the same perturbation can cause a different network, that was trained on a different subset of the dataset, to misclassify the same input.
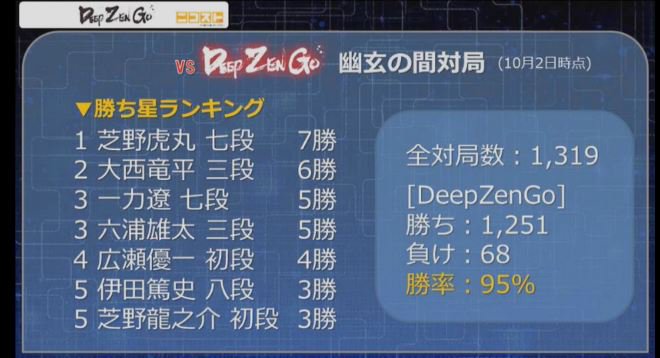
There is a good example, for visual learning, of such perturbations in this Quanta Magazine article, "Is AlphaGo really such a big deal?" (
https://www.quantamagazine.org/is-alpha ... -20160329/ ). Look for the picture of a dog. Perhaps, in go, the go position where DeepZen made a kyu level life and death error is one such perturbed position. My guess is that Deep Zen would have no trouble with the life and death problem by itself, or in other whole board contexts, but in this case the top side introduces a discontinuity so that the bottom side group got ignored.